
Download: source or SVMdark.exe - last updated: 9 July 2005
Download example files: train.txt validation.txt test.txt
The software can perform both classification and regression, the following example uses regression. For classification, replace the outputs with "1" or "-1".
Any field left blank in the interface will be treated as a zero.
This is an exercise in supervised learning, we are given the following input/output data. Given future inputs, we wish to predict (unknown) outputs.
| input 1 | input 2 | output |
| 7 | 0 | 7 |
| 9 | 1 | 10 |
| 4 | 6 | 10 |
| 3 | 8 | 11 |
| 9 | 4 | 13 |
| 3 | 8 | 11 |
| 5 | 4 | 9 |
| 6 | 0 | 6 |
| 3 | 8 | 11 |
| 4 | 5 | 9 |
| 0 | 1 | 1 |
| 3 | 8 | 11 |
| 9 | 0 | 9 |
| 3 | 0 | 3 |
| 2 | 9 | 11 |
| 1 | 4 | 5 |
| 7 | 9 | 16 |
| 0 | 9 | 9 |
| 1 | 8 | 9 |
| 2 | 3 | 5 |
Split the data into three sets (in the ratio 50%, 25%, 25%).
In each set, make the first column the output column and label the others 1:, 2:, etc.
Save as three separate text files, as follows.
Training set (train.txt)
7 1:7 2:0
10 1:9 2:1
10 1:4 2:6
11 1:3 2:8
13 1:9 2:4
11 1:3 2:8
9 1:5 2:4
6 1:6 2:0
11 1:3 2:8
9 1:4 2:5
Validation set (validation.txt)
1 1:0 2:1
11 1:3 2:8
9 1:9 2:0
3 1:3 2:0
11 1:2 2:9
Test set (test.txt)
5 1:1 2:4
16 1:7 2:9
9 1:0 2:9
9 1:1 2:8
5 1:2 2:3
Select "Regression".
Click the "Test file..." button and select validation.txt.
Fill in the other fields as shown below.
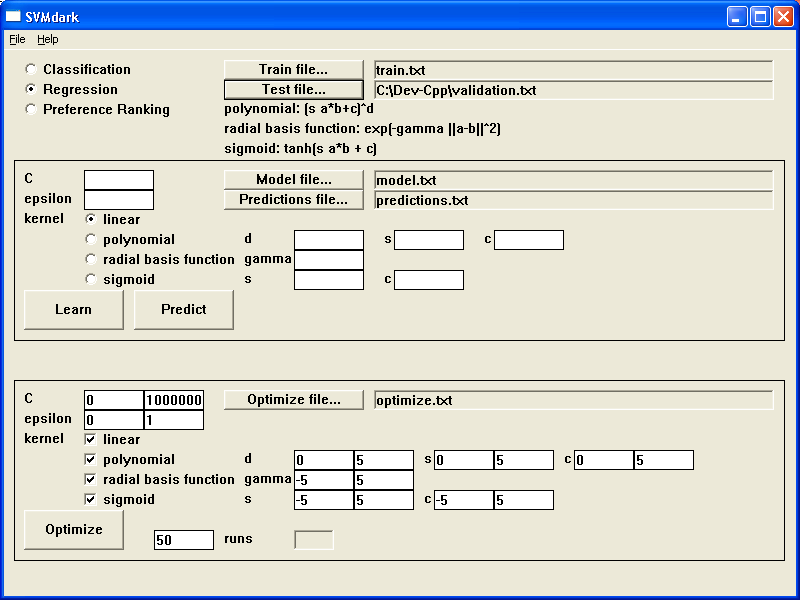
Click on the large "Optimize" button.
When the hour glass has gone, open the tab-delimited file "optimize.csv". Note the parameters used which produce a low MSE (mean squared error).
Reduce the number of potential models by "zooming in" on those which perform well on the validation set, repeat if necessary.
In this example, the linear kernel with a small value for epsilon performed best, so we narrow our search accordingly:
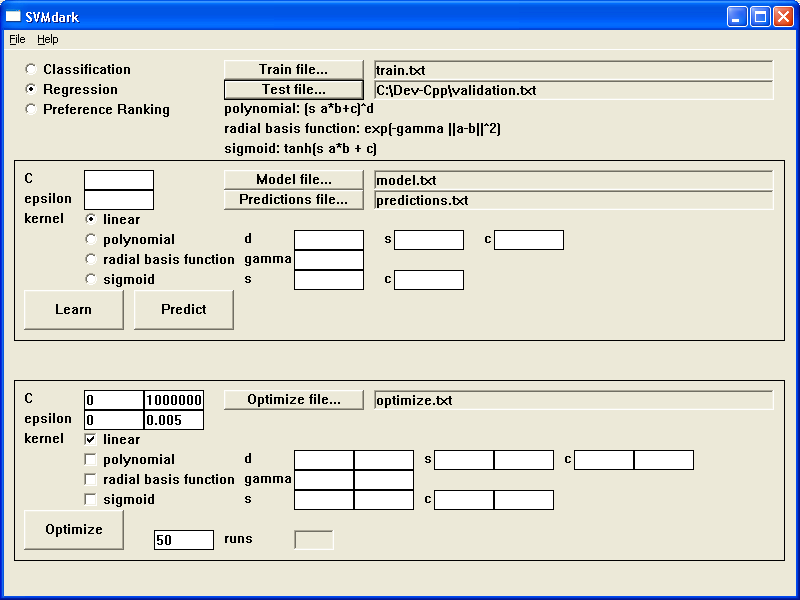
Again, inspect "optimize.csv" and identify the smallest MSE.
We select the parameters that performed optimally on the validation set.
Now, we select the test set - click the "Test file..." button again and select test.txt.
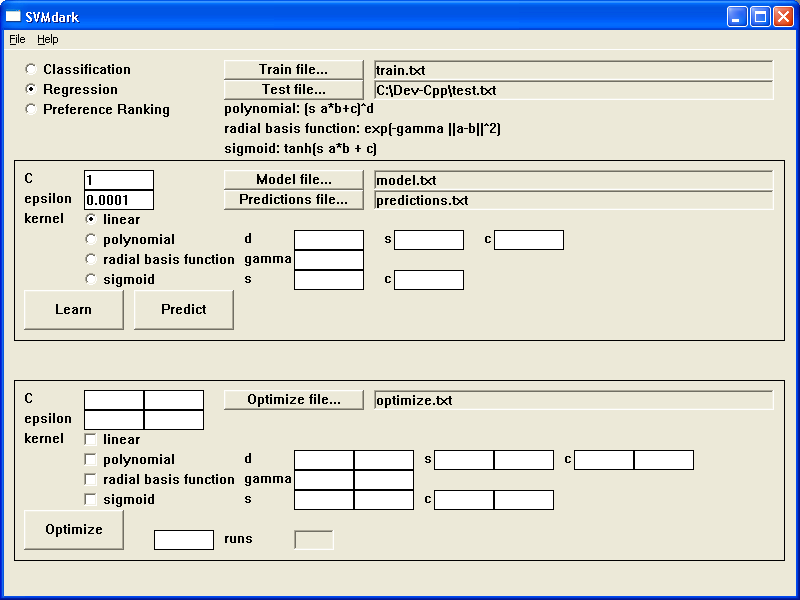
Click the "Learn" button.
Click the "Predict" button.
Inspect the file "predictions.txt".
Predictions:
5.0006471
15.999537
9.0003896
9.0003437
5.0006011
Remember the actual outputs:
5
16
9
9
5
Not bad, huh? That is because the above example was both linear and noise-free. However, it's with noisy nonlinear real-world data that the support vector machine shows its real strengths. Enjoy!
This software is free only for non-commercial use.
LightData Agent written by Ophir Gottlieb takes comma, space or tab delimited data and converts it into the required data format with colons, etc.
formatlibsvm my own code, which formats data for LIBSVM, SVMlight, TinySVM and SVMdark.
|
